
Knowing and understanding your customers is an important key to a company’s success. By understanding patterns of how customers work, how they use provided products or services, act on pricing and so on, a company can effectively meet customers’ needs and preferences and thus improve delivery to customers. However, obtaining an understanding of every customer is expensive both in terms of time and resources, and can be challenging for companies with large customer bases. Fortunately, many customers share comparable characteristics and often interact with the business in similar ways. By grouping customers according to combinations of these characteristics, the company can see new patterns and create tailored strategies for each group. But even for a company with a small amount of data, this can be problematic since hidden, high-dimensional patterns can exist in the data, which the traditional segmentation methods have difficulty finding. This is where machine learning comes in and by using clustering methods it is possible to identify and group customer behaviors in complex datasets.
The classical segmentation techniques are based on conventional analytical methods where you try to identify customer groups using comparison-analysis techniques such as cohort analysis. The problem with this is that these techniques have trouble handling high-dimensional data, and therefore all information in the data is not extracted and used. Machine learning and artificial intelligence clustering models can be used to improve this and get more advanced customer segmentation. These models can extract information from the data, making these models very powerful for supporting decision-making. They can identify customer segments based on the entire dataset, including the geographical, demographical, transactional, behavioural and psychological data. This means that the resulting segmentation is based on the entire dataset instead of analyzing each data dimension separately.
Clustering algorithms can generally be described as methods capable of organizing objects into groups based on similarities. A cluster is defined as a collection of objects which share similarities with objects in their cluster and are dissimilar to the objects belonging to other clusters. The methods are unsupervised meaning that the data is unlabeled and therefore not influenced by human opinion, as supervised learning methods can be. Instead, unsupervised clustering finds structures in a collection of unlabeled data. This makes the methods applicable to all sorts of datasets.
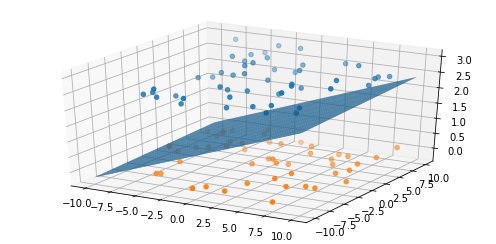
Going from low to high-dimensional data can be a massive advantage. An example of this can be seen in the visualization below, where the data can’t be clustered in two dimensions but when we add a third dimension, the data become separable. In this case, the data was separable using three dimensions but sometimes it requires even higher dimensions to find clusters; this is where machine learning and artificial intelligence models outperform traditional segmentation methods.

Decision Labs can help your organization define and implement clustering algorithms to enable your company to better understand your customers, in terms of both static demographics and dynamic behaviors, and hence improve business performance.


