

Kundsegmentering med hjälp av maskininlärning
Kundsegmentering med hjälp av maskininlärning
Taggar: Artificiell intelligens, Business intelligens, Affärsförståelse, Beslutsfattande
Att känna och förstå sina kunder är en viktig nyckel till företagets framgång. Genom att förstå hur kunderna arbetar, hur de använder de produkter eller tjänster som tillhandahålls, hur de agerar i samband med prissättning och så vidare, kan ett företag effektivt tillgodose kundernas behov och preferenser och därmed förbättra leveranserna till kunderna. Att få en förståelse för varje kund är dock dyrt både i form av tid och resurser, och kan vara en utmaning för företag med stora kundbaser. Lyckligtvis delar många kunder jämförbara egenskaper och interagerar ofta med företaget på liknande sätt. Genom att gruppera kunderna enligt kombinationer av dessa egenskaper kan företaget se nya mönster och skapa skräddarsydda strategier för varje grupp. Men även för ett företag med en liten mängd data kan detta vara problematiskt eftersom det kan finnas dolda, högdimensionella mönster i data, som de traditionella segmenteringsmetoderna har svårt att hitta. Det är här maskininlärning kommer in och genom att använda klustermetoder är det möjligt att identifiera och gruppera kundbeteenden i komplexa datamängder.
De klassiska segmenteringsmetoderna bygger på konventionella analysmetoder där man försöker identifiera kundgrupper med hjälp av jämförelseanalysmetoder som kohortanalys. Problemet med detta är att dessa tekniker har svårt att hantera högdimensionella data, och därför kan inte all information i data extraheras och användas. Maskininlärning och klustermodeller med artificiell intelligens kan användas för att förbättra detta och få en mer avancerad kundsegmentering. Dessa modeller kan extrahera information från data, vilket gör dessa modeller mycket kraftfulla för att stödja beslutsfattande. De kan identifiera kundsegment baserat på hela datasetet, inklusive geografiska, demografiska, transaktions-, beteende- och psykologiska data. Detta innebär att den resulterande segmenteringen baseras på hela datasetet i stället för att analysera varje datadimension separat.
Klusteralgoritmer kan generellt beskrivas som metoder som kan organisera objekt i grupper på grundval av likheter. Ett kluster definieras som en samling objekt som delar likheter med objekt i sitt kluster och är olik de objekt som tillhör andra kluster. Metoderna är oövervakade, vilket innebär att uppgifterna är omärkta och därför inte påverkas av mänskliga åsikter, vilket övervakade inlärningsmetoder kan göra. Istället hittar oövervakad klusterbildning strukturer i en samling av omärkta data. Detta gör att metoderna kan tillämpas på alla typer av datamängder.
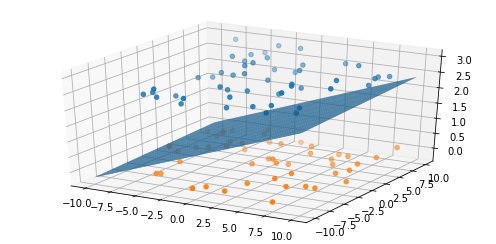
Att gå från låg- till högdimensionella data kan vara en enorm fördel. Ett exempel på detta kan ses i visualiseringen nedan, där data inte kan klusteras i två dimensioner, men när vi lägger till en tredje dimension blir data separerbara. I det här fallet var data separerbara med hjälp av tre dimensioner men ibland krävs det ännu högre dimensioner för att hitta kluster; det är här som modeller för maskininlärning och artificiell intelligens överträffar traditionella segmenteringsmetoder.

Decision Labs kan hjälpa din organisation att definiera och implementera klusteralgoritmer för att göra det möjligt för ditt företag att bättre förstå dina kunder, både när det gäller statisk demografi och dynamiska beteenden, och därmed förbättra affärsresultatet.